CALM CS 175: Project in AI (in Minecraft)
Video Report
The language generation and environment perception module currently runs separately, we are planning to pipe the modules together as of immediate next step.
Project Summary
We consider the problem of generating environment aware, style specific text snippets in Minecraft. Concretely, our agent will take as input the environment object string such as “dirt” and “diamond” retrieved from Minecraft and output style specific synthetic texts related to the input, such as horror stories and super hero stories.
Approach
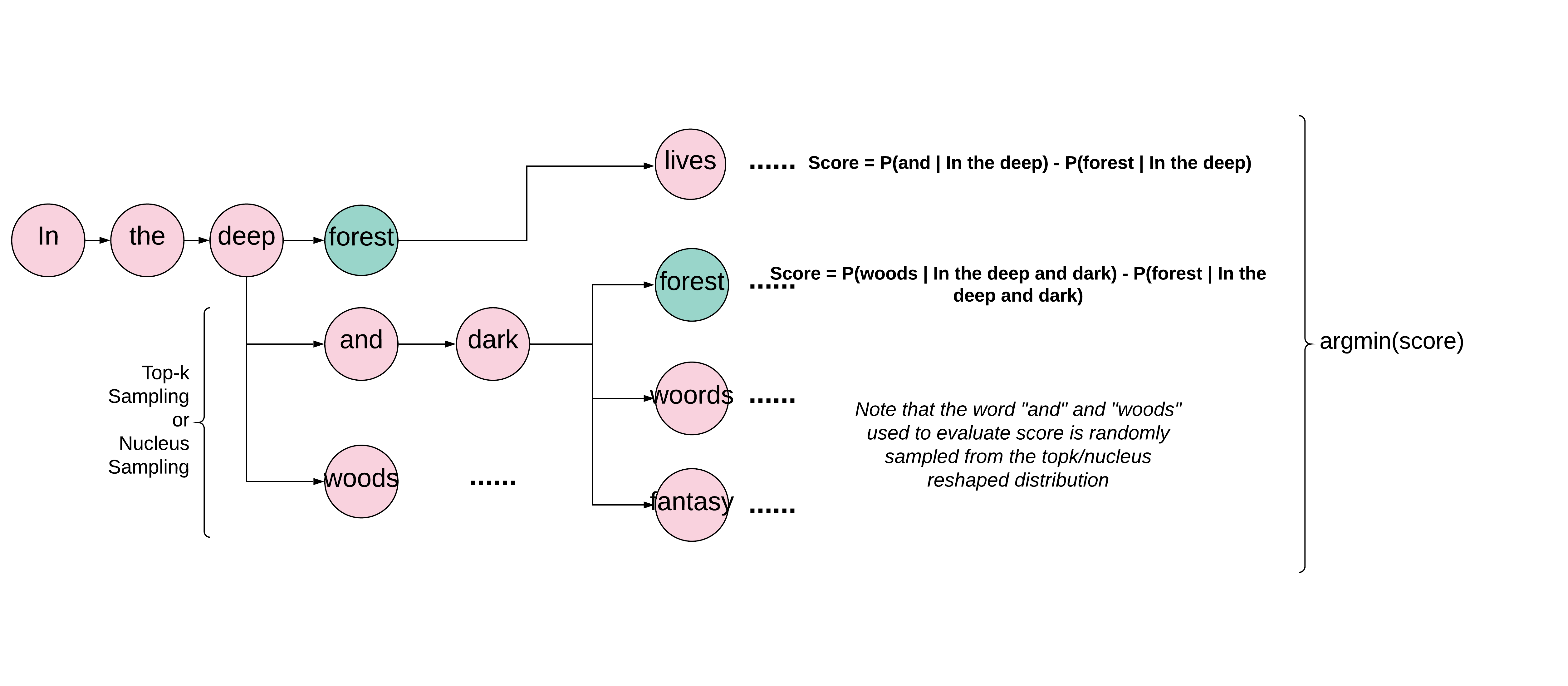
We choose pretrained GPT-2 model fine tuned on style specific corpus such as horror story and super hero stories for language generation. At each language generation step, the pretrained model ouputs a logits of corpus size that specifies the probability of the corresponding words to appear at the current position. Traditionally, the word chosen at each generation step is achived by approaches such as nucleus sampling and top-k sampling(see here).
To achieve context aware langauge generation, our system retrieves description of surrounding blocks from adjacent blocks of the agent(such as ‘diamond_block’) and returns a string that is common in natural language(‘diamond’). We then try to make the target word appear in our output text snippet by finding a position where the target word is most likely to appear. Formally, the context aware language generation task is defined as finding a sequence \((w_1,w_2,w_3... w_n)\) with an victim word \(w_v\) such that \(abs(p(target word \mid w_0, ... , w_{v-1})-p(w_v \mid w_0, ... , w_{v_1}))\) is minimized, while the raw probability of a certain word is sampled at each generation step after the word swapping happened is given by \(p(w_i \mid w_0, w_1, ... , target word, ... , w_{i-1})\)(prior to applying topk/nucleus sampling).
To find the optimal sequence, our system generates candidate sequence by computing the potential target word swapping loss \(abs(p(target word \mid h_{t-1})-p(chosen word \mid h_{t-1}))\) at each generation step t, and view the current sequence as a candidate hypothesis if such loss is smaller than a pre-defined threshhold. Upon generation of a hypothesis, the word swapping loss is assigned to that branch as a score. Meanwhile, the system will keep on the generation process with other possible cases where the word swap did not take place, untill a new position where the target word could be swapped in or end of generation steps is reached. After the exploration of candicate hypothesises is done, we choose the word sequence with lowest swapping loss as output.
Evaluation
| Style | Target word | Word seed | Text |
|---|---|---|---|
| drama | sword | Long long ago | :::: Long long ago , the sword master Yutai became possessed of his magic talent, transforming from human-type sword into the “Seven Stars of the Jade Buddha” when the Buddha was destroyed by a group of assassins |
| horror | pig | In the deep forest | :::: In the deep forest surrounding The Bahamas in 1964 a pig called Nino, a “ghost,” awake with fear from a nightmare, has entered an experimental serum and now exists only by a mysterious fate |
| super hero | lava | In the deep forest | :::: In the deep forest in Nevada, lava from above has erupted causing a series and unexpected geological collapses that destroy several surrounding communities while a small, humanoid creature called S.S. Spider, who can breathe flames that does |
Style coherent
To ensure the reults we generated are style coherent, we choose to use human evaluation metrics to ensure the ouputs are indeed of the intended style. Specifically, we randomly sample sentences with different styles from our system, and let human readers guess the genre of the generated sentence. We then pick the genre with the most vote from our group of reviewers as the guessed style of the text to be compared with intended style. We determine an output sample is style coherent if the human reviewer group reaches the same style as the intended style for generating that sample. Out of the eight sample examined, 75% samples style coherent(we plan to increase the test sample size after the generation algorithm is stablized in the future).
Syntactically sound
To ensure our method only impose minimal damage to the ability of language model to generate syntactically correct text, we use an open source grammar checker to check the suspected grammar errors in our generated text. Specifically, we pasted 15 generated samples into grammarly and found an average grammar error rate of 1 per sentence and overall grammarly grading score of 75(description of grammarly score). Again, we plan to extend the test sample size when our algorithm is set in the future.
Remaining Goals and Challenges
We plan to improve our system by both improving our generation algorithm and the ease-of-use of the system. In the following periods, we plan to change our current usage of top-k sampling to nucleus sampling to enhance quality of our generated text. Meanwhile, the current system lacks the ability to deal with composite blocks in the environment, for example, the system cannot retrieve the word “tree” from the environment as trees are represented in Minecraft as the composition of wood blocks and leaf blocks. Finally, we plan to augment our evaluation process by testing more generated test snippets and trying other helpful evaluation metrics.